Redis
本文最后更新于:2 小时前
走进Redis
Redis系统架构
特性
内存NoSQL数据库
- 支持key-value类型
- 支持 GET PUT DELETE 形式访问操作(上层业务应用可直接使用)
高性能
百纳秒、微妙级别响应延迟
丰富的数据类型
- Key: String
- Value: 多种类型
- Value: String, List, Hash, Set, Sorted Set
可持久化保存数据
- 支持对数据库做内存快照(RDB)
- 支持日志记录写操作(AOF)
- 对比memcached(另一种键值数据库)
高可用
- 支持主从集群
- 读写分离、故障切换
高可扩展
- 支持切片集群,例如Recis Cluster, Codis等
Redis主要数据结构
不同Value类型使用不同底层数据结构
- 兼顾性能和空间开销
- 有序集合和无序集合的设计选择
- 哈希表的实用主义:rehash影响
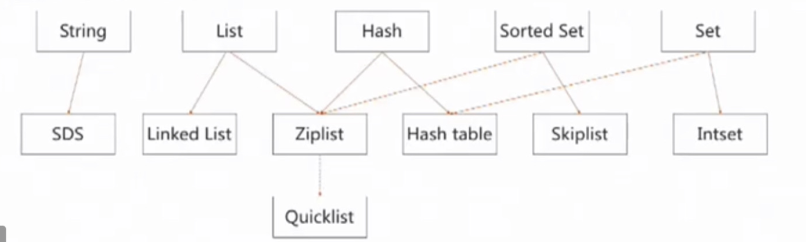
基本数据类型
- Key : Value
- Value多样化
常见Value类型-String
- 二进制安全的字符串,最大512MB
- 使用广泛,数值、字符串、图片等
常见Value类型-List
- 双向链表,支持POP和PUSH
- 排行榜、关注列表、消息队列都能用
常见Value类型-Hash
- 字典,一个Key对用多个value
- 结构化数据
常见Value类型-Set
- 无序集合,支持元素去重和集合操作
- 社交应用中共同关注、共同好友
常见Value类型-Sorted Set
- 有序集合
- 排行榜
常见Value类型-Bitmap
- 位图,一个bit位表示一个状态
- 用户签到,状态统计
常见Value类型-HyperLogLog
- 基数统计,一个集中中不重复的元素个数
- 用户日活、月活统计
Redis高性能关键技术
影响Redis性能的关键因素
| 操作类型 | 潜在风险 |
|---|---|
| 键值对操作 | O(N)操作 集合操作 bigkey |
| 持久化操作 | AOF日志同步写 RDB fork |
| 网络IO | |
| 主从复制 | |
| 应用混布 | 性能干扰 |
Redis高可用关键技术
Redis主从集群
- 主从复制
- 全量复制 + 增量复制
故障切换
- 哨兵机制负责故障切换
- 监听主从实例的心跳
- 根据心跳信息判断主从实例是否下线:主观下线 + 客观下线
- 执行主从切换:基于投票机制确定切换的leader + 选主 + 切换
Redis高可扩展关键技术
高可扩展方法
- Scale-up:扩展单个实例的容量
- Scale-out:增加多个实例,共同分担压力
Scale-up的不足
- 单实例物理容量有限
- 主从复制压力大
- 持久化压力大
Redis Cluster
- 去中心化集群技术:没有中心化的转发点,避免单点故障
- 客户端需支持Cluster相关命令
数据切片
- 16483个哈希槽
- CRC16(key) % 16483
- 支持平均分配哈希槽或手动分配
客户端请求转达
- 基于Gossip的哈希槽分配信息传递
- 客户端缓存哈希信息
- MOVED重定向机制
Codis
- Redis Cluster方案前的业界常用方案
Codis proxy
- 请求转发
- 支持RESP协议,兼容现有客户端
Codis server
- 二次开发德实例
- 支持额外的数据结构
- 支持数据迁移操作
Codis dashboard/fe
- 集群管理及Web界面
- 增删codis server,进行数据迁移
Zookeeper集群
- 保存集群元数据信息,例如数据位置
Redis Cluster vs. Codis
- 成熟度:Codis应用广泛, Redis Cluster也有一定使用
- 客户端兼容性:Codis proxy直接兼容面向单实例的客户端,Redis Cluster需要二次开发客户端
- 数据迁移:Codis支持异步迁移,性能影响较小
- 新增命令和特性:Codis基于Redis3.2.8开发,并且并不支持所有命令
总结
- Redis借助于内存数据库、单线程+异步子进程/线程模型
- Redis充分利用不同数据结构和空间特点,支持丰富的value类型
- Redis性能至关重要,抓住Redis关键机制,避免操作阻塞、内存溢出
答疑
Q1. Redis的线程模型是怎么单线程支持高并发的?
首先有个概念,并发和并行是不一样的。并行是指同一时间做很多事情,并发是指同一时间有多个请求。Redis的高并发指的是指很快地处理并发过来的请求,具体实现主要是依靠Linux操作系统。Redis本身的工作线程是单线程的,需要顺序地从网络读取数据,分析数据后执行,再把结果返回给客户端,都是在同一个线程去做的。这些客户端是如何激活的呢,主要是Redis用了操作系统提供的epoll(I/O多路复用技术)。
Q2. 给Redis增加CPU核心会没有性能提升吗?
在4.0之前,Redis的工作线程只有一个。正常情况下2-3核是够用的,添加更多CPU核心对于主线程来说确实是没有太大的效果的。
在6.0开始,Redis也开始支持多线程了,但处理用户请求还是一个线程,所有的请求在从操作系统获取过来还是串行地执行的。但网络这一块是多线程的,读网络和写网络是多线程。主线程从epoll里面收割事件,拿到所有活跃时间后,分发给IO线程,接着再有主线程做收集,再执行(执行的过程也是单线程串行),再将结果分发给IO线程。整个过程是“分-总-分”的模式。网络I/O在读写网络的时候是可以多线程并行的,但是执行逻辑还是要串行执行的。在这个时候给Redis分配多个CPU核心,性能是会提升上去的。
Q3. Redis和Memcached对比?
Redis可以当作Memcached的超集,Memcached本身就支持简单的key-value,比如String。Redis在大部分场景都可以覆盖Memcached。但是有一点,Memcached有版本的概念,有的操作是Redis的社区版是不支持的。如果大家想尝试这种操作的话,阿里云有Redis有企业版,Redis在4.0之后支持Module,阿里云开发了TairString等Module。
Q4.能把Redis直接当作持久化的DB吗?
主要看业务场景。如果只考虑单机,Redis本身提供AOF操作,且AOF可以配置fsync什么时候调用。一种是Redis不主动做fsync,如果Redis挂掉后,完全依赖操作系统。另外一种是每秒调用一次fsync,如果在极限情况下宕机,有可能丢一秒钟的数据。还有一种叫always,每次写AOF后都会主动调用fsync,可以严格保证Redis数据可以异步地写到磁盘上,但always对性能有一定影响。
主从版要复杂一些,虽然有fsync可以保证数据全都落盘,但主备Redis目前还不行,因为它是异步进行复制的,在实际操作上有可能会丢失一些数据。如果对小概率的丢失数据的场景能够容忍,还是可以当作持久化DB的,如果无法容忍这种情况,最好Redis还是作为缓存来使用。
Q5.Redis数据同步有哪些方案呢?
社区版本身有很多开源工具基于Redis的主从复制协议开发一些同步方案,简单地说,主从同步是没什么问题的,但是跨域的话,因为Redis的主从同步都是在内存里进行的,没有持久化。如果数据通道一旦断开,做同步就比较消耗时间和消耗资源。如果想跨域同步,建议还是自己带一套额外的中间件来做,比如从云端拉数据,再推到目的端。
Q6.请问redis不设置密码时为什么会被挖矿,是因为有安全问题吗?
如果Redis不设置密码,所有人都可以访问,这时候有些操作是有可能获取到你的整机的执行权限,所以大家在运维Redis的时候一定要注意设置密码,云上都是强制必须设置密码的。
Q7.购买阿里云Redis集群的时候,对于4分片16G的配置,对于可用的内存存储是4G还是6G?这个分片越多访问速度越快还是高可用越稳定?
云上的配置通常是写几分片几G,比如4分片16G是指4个分片,每个分片16G,总共的可用内存就是4*16G,这是一个集群整体的可用内存情况。但它毕竟是分片的,所以数据是存储在不同的分片上面,比如A算出来Hash的结果,B算出来Hash的结果,有可能是分配在不同的分片上的,需要注意存储的倾斜。一般来讲,随机分布是不会出现很明显的倾斜的。
Q8.线上环境的redis 出现过2次数据全部丢失,请问除了手动flushdb的情况,还有什么情况回导致数据全部丢失呢?
如果实例没有发生过宕机,有可能就是手动flushdb造成的情况。
如果宕机,且没有开数据持久化,有可能数据就全部丢了。
还有一种极端情况,虽然Redis有maxmemory这种设置,但是maxmemory指的是运行时可用的内存,并不是数据的内存。如果在实际运行中,耗费的内存已经超过一个G,可能会触发evict逐出,如果数据的设置又满足逐出策略的话,也是有可能发生数据丢失的。
Q9.Redis6.0后请求并发,是否保证顺序呢?
从单个链接上来看,即便时IO多线程,也是串行的。一个连接也是读网络,执行,返回数据,执行下一个命令,返回数据……从多个连接的情况来看,比如连接A B C,他们的读写是可以并行的,所以不用担心一个客户端是否可能乱序。
Q10.Redis不同的数据类型操作的时间复杂度都是O(1)吗?
Memcached都是O(1),但Redis不是,有很多数据类型,O(n)和O(logn)都是比较多的。
Q11.Redis的操作延迟在百纳秒/微妙级别,但是考虑到网络上的耗时,同机房可能在1~3毫秒,从客户端角度来说,这个百纳秒的性能是体现不出来的吗?
是的。性能分两个方面,吞吐和时延。网络本身的物理时延没有办法避免,但吞吐如果有多个客户端同时访问,吞吐上是可以达到很高的并发量的。
Q12.大小达到多少才算是bigkey?
①本身的数据长度,通常千以上的级别就是比较大的。②本身的体积,也就是占用的内存,Redis默认最大上限是512MB。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!