十大经典排序算法C++(已更新6/10)
本文最后更新于:2 小时前
冒泡排序
如果序列已经是有序的,我们可以对冒泡排序进行优化
每趟排序时,判断一下是否已经交换过元素。如果没有交换过元素,证明序列已经有序,排序提前结束。
//冒泡排序
vector<int> bubbleSort(vector<int>& nums) {
if ( nums.size() < 2 ) return nums;
//设置是否交换标志
bool isswap;
for ( int i = nums.size()-1; i > 0; i-- ) {
//初始化标志为为交换
isswap = false;
for ( int j = 0; j < i; j++ ) {
if ( nums[j] > nums[j+1] ) {
nums[j] ^= nums[j+1];
nums[j+1] ^= nums[j];
nums[j] ^= nums[j+1];
//更改初始化标志为已交换
isswap = true;
}
}
//判断标志位
if ( isswap == false ) return nums;
}
return nums;
}使用冒泡排序在LeetCode 912题中会出现不通过(运行超时)的错误
选择排序
从头至尾遍历序列,找出最小的一个元素,和第一个元素交换,接着从剩下的元素中继续这种选择和交换方式,最终得到一个有序序列。
//选择排序
vector<int> selectionSort(vector<int>& nums) {
if ( nums.size() < 2 ) return nums;
for ( int i = 0; i < nums.size()-1; i++ ) {
int minindex = i;
for ( int j = i+1; j < nums.size(); j++ ) {
if ( nums[j] < nums[minindex] ) {
minindex = j;
}
}
if ( minindex != i ) {
swap(nums[minindex], nums[i]);
}
}
return nums;
}选择排序一趟只选取最小值,优化的办法就是一趟把最小值和最大值都选出来,最小的放在左边,最大的放在右边。优化后的方法循环趟数将减半。
vector<int> selectionSort2(vector<int>& nums) {
if ( nums.size() < 2 ) return nums;
int left(0), right(nums.size()-1);
int minindex, maxindex;
while ( left < right ) {
minindex = maxindex = left;
//找出最小元素和最大元素
for ( int i = left; i <= right; i++ ) {
if ( nums[i] < nums[minindex] ) {
minindex = i;
}
if ( nums[i] > nums[maxindex] ) {
maxindex = i;
}
}
//判断、交换
if ( minindex != left ) {
swap(nums[minindex], nums[left]);
}
if ( maxindex == left ) {
maxindex = minindex;
}
if ( maxindex != right ) {
swap(nums[maxindex], nums[right]);
}
//索引增减
left++, right--;
}
return nums;
}插入排序
插入排序类似斗地主,抓牌以后将手里的牌进行排序
插入排序原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。
//插入排序
vector<int> insertionSort(vector<int>& nums) {
if ( nums.size() < 2 ) return nums;
//从第2个数开始选取
for ( int i= 1; i < nums.size(); i++ ) {
int temp = nums[i];
//在待插入之前的元素中查找应该插入的位置
int j(i-1);
while ( j >= 0 && temp < nums[j] ) {
nums[j+1] = nums[j];
j--;
}
nums[j+1] = temp;
}
return nums;
}插入排序的缺点:
- 需要寻找插入的位置
- 需要移动元素
在查找位置时,我们引入二分查找提高查找的速率
对于插入排序,有以下几种优化方案:
对已排好序的序列,采用二分查找法
携带多个元素
插入排序原本每次只寻找一个元素的插入位置,将这里优化为取出多个元素后对这多个元素进行排序,然后同时查找应插入的位置
数据链表化
希尔排序
快速排序
快速排序算法_哔哩哔哩 (゜-゜)つロ 干杯~-bilibili
快速排序是C.R.A.Hoare于1962年提出的一种划分交换排序。它采用了一种分治的策略,通常称其为分治法(Divide-and-ConquerMethod)。
该方法的基本思想是:
- 先从数列中取出一个数作为基准数。
- 分区过程,将比这个数大的数全放到它的右边,小于或等于它的数全放到它的左边。
- 再对左右区间重复第二步,直到各区间只有一个数。
//快速排序
vector<int> quicksort(vector<int> &nums, int L, int R) {
if ( nums.size() < 2 || L >= R ) return nums;
int left(L), right(R);
int pivot = nums[left];
while ( left < right ) {
while ( left < right && nums[right] >= pivot ) {
right--;
}
if ( left < right ) {
nums[left] = nums[right];
}
while ( left < right && nums[left] <= pivot ) {
left++;
}
if ( left < right ) {
nums[right] = nums[left];
}
if ( left >= right) {
nums[left] = pivot;
}
}
quicksort(nums, L, right-1);
quicksort(nums, right+1, R);
return nums;
}归并排序
归并排序(Merge Sort)就是将已经有序的子数列合并得到另一个有序的数列。归是归并的归,不是递归的归,归并排序就是合并排序。
//归并排序
vector<int> mergeSort(vector<int> &nums, int left, int right) {
if ( left >= right ) return nums;
int mid = (left + right) / 2;
//递归调用先对左右子数组进行排序
mergeSort(nums, left, mid);
mergeSort(nums, mid+1, right);
//临时存放合并结果
vector<int> temp(right-left+1);
int i(left), j(mid+1);
int cur(0);
while ( i <= mid && j <= right ) {
temp[cur] = nums[i] <= nums[j] ? nums[i++] : nums[j++];
cur++;
}
while ( i <= mid ) {
temp[cur++] = nums[i++];
}
while ( j <= right ) {
temp[cur++] = nums[j++];
}
for ( int i = 0; i < temp.size(); i++ ) {
nums[left+i] = temp[i];
}
return nums;
}希尔排序
希尔排序是插入排序的一种,它是针对直接插入排序算法的改进,由D.L.Shell于1959年提出而得名。
在插入排序中,如果靠后的元素较小,它就需要交换多次才能够来到前面。而希尔排序改进了这种做法:带间隔地使用插入排序,使得最后地间隔为1时,就是标准地插入排序,而此时地整个待排序数组已经是几乎有序了。
希尔排序基本思想把待排序的数列分为多个组,然后再对每个组进行插入排序,先让数列整体大致有序,然后多次调整分组方式,使数列更加有序,最后再使用一次插入排序,整个数列将全部有序。
每次分组都会减小间隔,但是每次排序后,都没有将上一次间隔的排序损坏
希尔排序的优势:
- 减少查找次数
- 减少移动元素次数
希尔排序对于增量的选取:
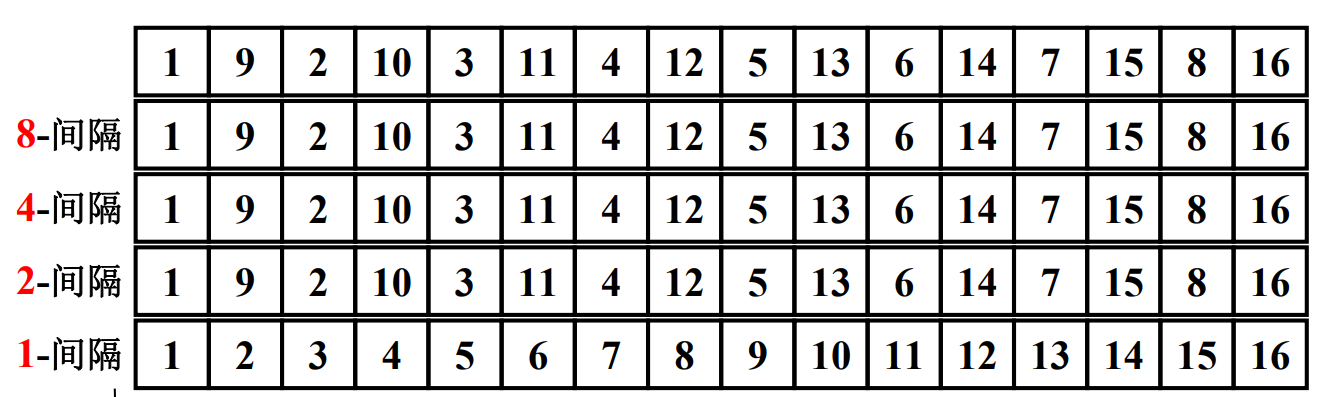
在这个比较极端的例子中,我们可以看到,当选取8、4、2、1作为增量的时候,会出现前面三趟排序都白做的情况,最后使得元素有序还是依靠的间隔为1时的最后一次标准插入排序。出现这种情况的原因是:增量元素不互质,所以小增量可能根本不起作用。
对于增量的选取,有很多学者都有自己的猜想,比较广为人知的两种增量序列:
Hibbard增量序列
Dk = 2k - 1 相邻元素互质
最坏情况:T = O(N3/2)
猜想:Tavg = O(N5/4)
Sedgewick增量序列
{ 1, 5, 19, 41, 109, … }
—— 9 x 4i - 9 x 2i + 1 或 4i - 3 x 2i + 1
猜想: Tavg = O(N7/6), Tworst = O(N4/3)
在需要排序的元素比较大时,使用希尔排序+Sedgewick增量序列能获得比较好的效果。
但是在接下来的代码中,将使用Knuth增量序列,因为我菜,不服你来写
//希尔排序
void insertionForDelta(vector<int> &nums, int gap, int i) {
int temp = nums[i];
int j = i;
while ( j >= gap && nums[j - gap] > temp ) {
nums[j] = nums[j - gap];
j -= gap;
}
nums[j] = temp;
}
vector<int> shellSort(vector<int> &nums) {
if ( nums.size() < 2 ) return nums;
int h(1);
while ( 3 * h + 1 < nums.size() ) {
h = 3 * h + 1;
}
while ( h >= 1 ) {
for ( int i = h; i < nums.size(); i++ ) {
insertionForDelta(nums, h, i);
}
h /= 3;
}
return nums;
}本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!